Movement as language.
In natural language, words emerge from compositions of phonemes. In motor control, movement segments emerge from compositions of submovements. We exploit this parallel: parse the accelerometer stream into segments at acceleration zero-crossings, encode each with a small CNN, and let a Transformer reason over the resulting sequence with masked reconstruction.
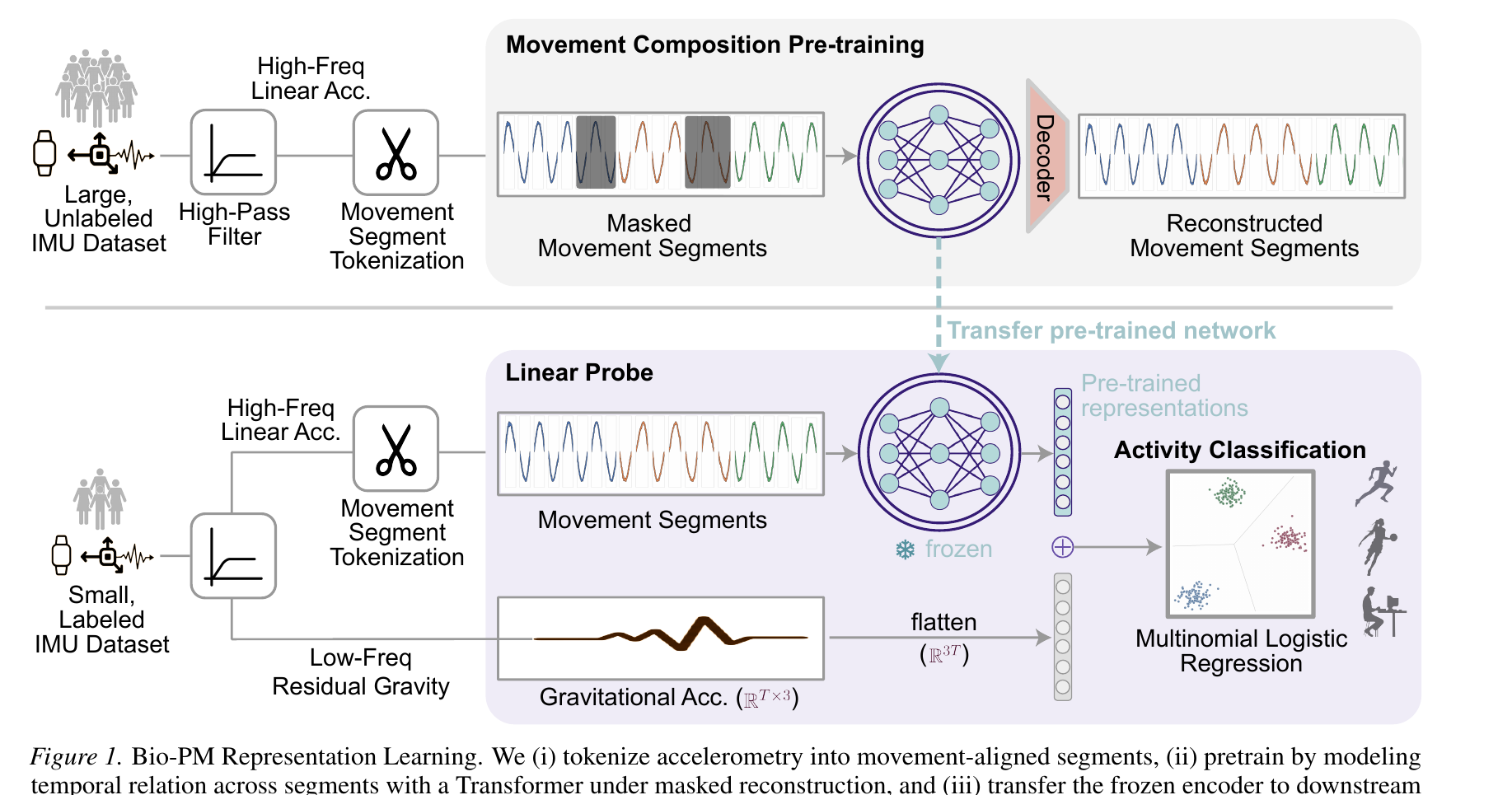
Figure 1. Bio-PM representation learning. We (i) tokenize accelerometry into movement-aligned segments, (ii) pretrain by modeling temporal relations with a Transformer under masked reconstruction, and (iii) transfer the frozen encoder to downstream HAR for linear probing.
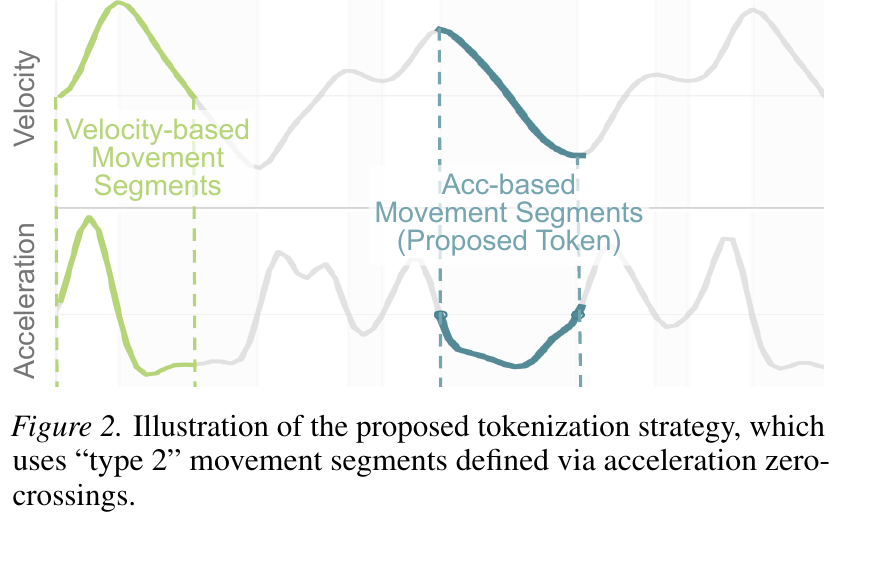
Figure 2. Illustration of the proposed tokenization strategy, which uses "type 2" movement segments defined via acceleration zero-crossings.